
연습장
14. 둘만의 암호 본문
문제해석

abcde fghij klmno pqrst uvwxy z
a 기준 index 5 만큼 뒤의 알파벳은 -> b c d e f -> f 이지만 skip 에 b d 가 있으므로 2칸 더 이동한 h 가 된다.
u -> z 이지만 skip w 1칸 -> a
k -> p
s -> x 지만 skip w 1칸 -> y
happy 가 된다.
문제를 해결하기 위해선 abcdefg 의 알파벳 순서를 컴퓨터에게 알려주어야한다.
2가지 방법이 있다.
1. str = " abcdefghijklmnopqrstuvwxyz" 의 문자열을 변수로 만들어서 사용하는 방법
2. 아스키 코드를 사용하는 방법
print(ord("a")) # 97
print(ord("z")) # 122
"a" 의 5번째 뒤의 알파벳을 확인하는 코드는 다음과 같다.
print(chr(ord("a")+5)) # f
그럼 여기서 skip 에 포함된 단어를 건너뛰게 하려면
다음과 같이 skip_list 를 만들고
# skip_list
skip_list = []
for jump in skip:
skip_list.append(ord(jump))
skip_list.sort()
print(skip_list)
skip_list 의 각 원소가 a~f(97~102) 사이에 몇개 있는지 확인하면 된다.
전체 코드를 만들면 다음과 같다.
def solution(s, skip, index):
answer = ''
# skip_list
skip_list = []
for jump in skip:
skip_list.append(ord(jump))
skip_list.sort()
# main
for char in s:
# skip 횟수
temp = 0
# skip 판단
for jump in skip_list:
if (ord(char) < jump) and (jump <= ord(char)+index+temp):
temp += 1
answer += chr(ord(char)+index+temp)
return answer

다음과 같이 "a" 가 아닌 "{" 가 나온다. 이는 z 이후 다시 a 로 가도록 조치를 하지 않은 결과로
# skip_list
skip_list = []
for jump in skip:
skip_list.append(ord(jump))
skip_list.sort()
# main
for char in s:
# skip 횟수
temp = 0
# skip 판단
for jump in skip_list:
if (ord(char) < jump) and (jump <= ord(char)+index+temp):
temp += 1
# z 를 넘어갈 경우
if ord(char)+index+temp > 122:
answer += chr(ord(char)+index+temp-26)
else :
answer += chr(ord(char)+index+temp)
하고 제출하니 테스트 실패 케이스가 굉장히 많다. 즉 예외 케이스가 많다는 뜻.
물론 위의 코드를 수정할수도 있지만
1. str = " abcdefghijklmnopqrstuvwxyz" 의 문자열을 변수로 만들어서 사용하는 방법 으로 해결하는게 조금 더 쉬울 것 같다.
# 순서 문자열 ( 2번 반복하여 z 다음 a가 되도록한다)
my_string = "abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
# skip 문자열 제거
for i in skip:
my_string = my_string.replace(i,'')
print(my_string) # acefghijklmnoprstuvxyzacefghijklmnoprstuvxyz
과 같이 잘 제거된것을 알 수 있다.
제거된 문자열에서 특정 문자의 위치를 알아낸뒤 index 만큼 더한 문자를 반환 하게 되면 된다.
for char in s:
print(my_string.find(char))

찾은 문자열에 index 만큼 더한 값을 인덱스 값으로 사용하여 문자에서 출력
for char in s:
answer += my_string[my_string.find(char)+index]
def solution(s, skip, index):
answer = ''
# 순서 문자열
my_string = "abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
# skip 문자열 제거
for i in skip:
my_string = my_string.replace(i,'')
for char in s:
answer += my_string[my_string.find(char)+index]
return answer
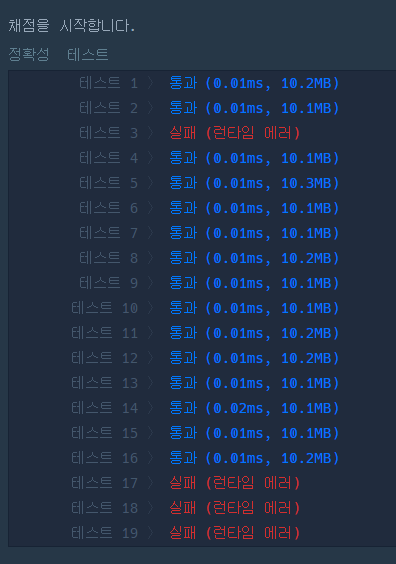
코드는 간결해졌지만 런타임에러가 나온다. 무언가 오류가 있다는 뜻.
여기서는 아마 index 범위 오류 가 아닐까 싶다.
다음과 같이 테스트 케이스를 추가해보았다.

z 의 문자를 skip의 최대 가능갯수인 10개 만큼 넣고 index의 최대값인 20을 넣을 경우

다음과 같은 인덱스 오류가 나타난다.
총 26개의 알파벳중 10개를 뺀 16개 중에서
1-16 & 1-16 인 32개 중
16번째에서 + 20 번째 뒤를 알려달라고 했으니 36번째 의 원소 값을 물어보는 거고 이는 32개의 my_string 범위에서 벗어나는 경우 이다. 따라서 string 을 한번더 붙여준다.
def solution(s, skip, index):
answer = ''
# 순서 문자열
my_string = "abcdefghijklmnopqrstuvwxyz"
my_string = my_string * 3 # 전체 문자열을 3번 반복하도록한다.
# skip 문자열 제거
for i in skip:
my_string = my_string.replace(i,'')
for char in s:
answer += my_string[my_string.find(char)+index]
return answer
물론 이 코드도 skip 갯수와 index 범위가 바뀐다면 더 많은 기본 문자열 my_string 을 반복해야 될 수 있다.



