
연습장
01. ML 본문
기본 개념 복습겸 정리
1시간 만에 머신 러닝 개념 따라 잡기
https://www.youtube.com/watch?v=cYI85HFgFeg
1. Machine Learning 이란?
데이터를 학습해서 패턴을 찾고 규칙을 만드는며 이를 활용하여 원하는 문제를 해결

Learning Algorithm
데이터를 가장 잘 표현하는 수식이 어떤것인지, 이를 찾아내는것

2. Machine Learning 으로 풀 수 있는 문제 유형

Supervised (지도학습) : data labeling , 정답이 있음
Unsupervised (비지도학습) : 정답이 없음
Reinforcement (강화학습) : 상황에 따라 답이 바뀜

Supervised Learning
문제(input) 와 정답(label) 을 같이 넣어주며 학습을 진행하고 예측(prediction) 을 진행하여
예측된 값을 정답(label) 과 비교하여 틀릴경우 알고리즘을 (Machine Learning Algorithm) 수정한다.
Classification (분류)
- Spam detection (스팸 탐지)
- Customer churn prediction (고객 이탈 예측)
Regression (회귀)
- House price prediction (주택 가격 예측)
- Demand forecasting (수요 예측)

Unsupervised Learning
단순하게 데이터와 문제 (3개의 그룹으로 나누고 싶다) 를 제공 (정답 x)
Clustering (클러스터링 , 군집)
- Customer segmentation (고객 세분화)
Density Estimation (차원 축소)

Reinforcement Learning
상 , 벌칙을 주며 가장 많은 보상을 받도록 학습하게 됨
Self Driving Car (자율주행)
Robots (로봇)
3. Machine Learning 작업 순서

Real-World Problem : 현실의 문제
- ML Problem Framing : 머신러닝의 문제로 변형
Define ML Problem : 머신러닝의 문제로 재정의
- Raw Data : 가공되지 않은 데이터
Data Preparation : 학습 가능한 데이터 준비
Build : 실제 코딩, 모델을 만드는 과정
Training : 모든 데이터를 넣어 모델 학습
Deploy : 실제 서비스에 적용하기 위한 과정

머신러닝이 해결할 수 있는 부분은 한정적이며
현실적인 부분을 어떻게 반영해야 머신러닝으로 해결 할 수 있을지?
데이터 수집, 어떤 알고리즘 (예측, 분류, 군집... ) , 입력 출력 설계 ,


수학적인 모델의 파라미터 값을 구하는게 최종 목표 이며
현실의 입력값을 숫자로 바꿔 주는게 중요하다.


카테고리성 데이터를 숫자로 변환, 전체 카테고리중 어디에 속하는지
Feature : 숫자로 변환된 ML 알고리즘의 입력 데이터
4. Machine Learning 학습을 위한 입력 데이터 가공하기 - Feature Engineering


차원이 커지며 컴퓨팅 리소스가 증가.
MNIST : 손글씨 , 픽셀이 차원이 됨
Farm Ads : 광고 단어 , 단어하나가 차원이 됨
차원의 저주를 풀기 위해서 Feature Engineering 잘 해야한다.
5. ML과 최적화 문제 - Loss Function & Gradient Decent method (경사하강법)

어떤 직선이 가장 적합한가? 데이터를 가장 잘 나타내는것은? -> 평가기준이 필요하게 됨

Error : 식의 값과 실제 데이터 값의 차이
f(x) = W*x + b 로 나타낼 수 있으며 기울기 W 와 절편 b 를 찾는 과정이며
여러개의 직선 중에서 Loss 함수가 가장 작아지는 식을 찾는게 목표

처음에는 무작정 추측 (찍는다) , 그 값보다 작아지는 다음 세타(오차) 값을 계속 찾아내서 가장 작은 세타 값을 찾는다.
세타는 w, b 의 함수로 그려질 수 있다.

Gradient Descent (경사하강법) : 기울기가 작아지는 방향으로
모델을 학습하기 이전에 알려줘야 하는 값 3가지 (하이퍼파라미터)
Learning Rate , 초기값 , batch size
기계학습 문제를 최적화 문제로 변형하기 때문에 필요함


6. Machine Learning 학습 속도와 모델 성능 향상을 위한 Hyper Parameter Tuning

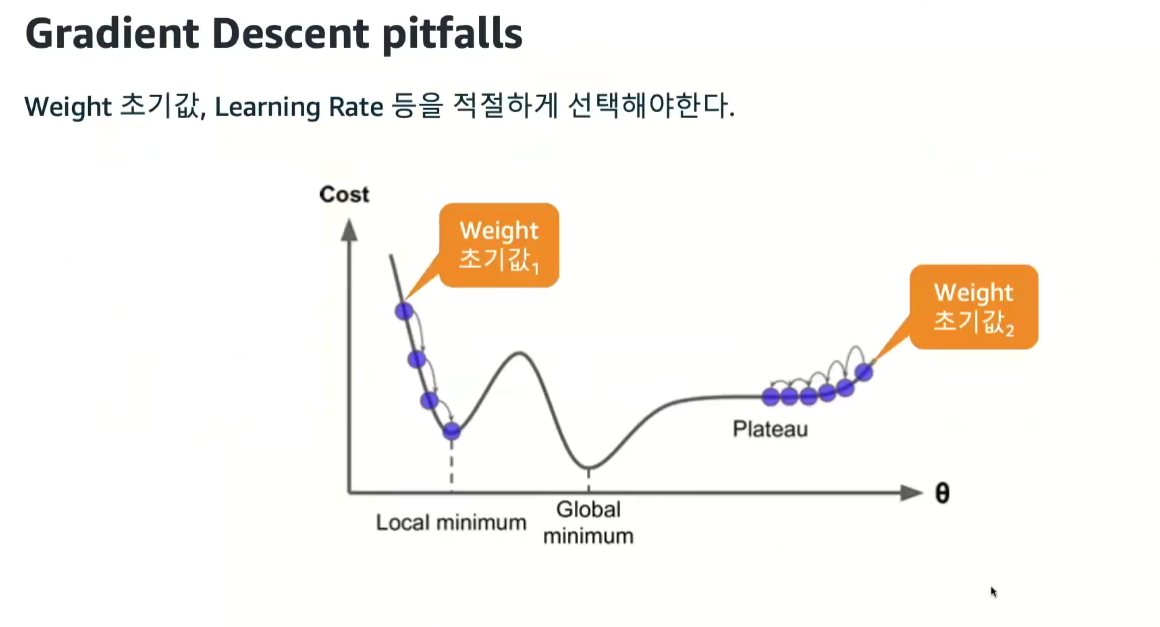
초기값에 따라서 Local minimum , Plateau 상황에 빠져서 Global minimum 에 도달하지 못하게 된다.

batch size : 한번에 처리할 데이터의 양
full-batch : 전체 데이터를 한번에 다 사용
mini-batch : 데이터를 나눠서 사용
Stochastic : batch size 가 1 일 경우
학습 속도가 달라지며 최적에 값에 잘 찾아가는지도 고려해야한다.

7. 미래를 위한 준비 - 데이터 나누기 (Train / Validation / Test )

가지고 있는 데이터로 학습을 진행하지만 결과물의 경우에는 한번도 사용한 적이없는 데이터에 대해서 모델을 적용해야 함, 따라서 학습할 데이터를 나눠서 진행한다.


8. Machine Learning 모델 선택 시 주의할 점 - Overfitting vs Underfitting


Underfitted : 모델이 너무 단순하다면 전체 데이터를 잘 표현하지 못함
Overfitted : 모델이 복잡하면 현재 데이터에는 잘 맞지만 미래의 데이터에는 맞지않게 됨
학습곡선을 그려보고 가장 적절한 모델을 선택
9. 여러가지 Machine Learning 모델 결합하기 - Ensemble method

여러 모델의 의견을 취합해서 하나의 결과를 낸다.
10. Deep Learning

인공지능 > 머신러닝 > 딥러닝

생물학적 뉴런을 수학적 인공 뉴런으로 생성 -> 퍼셉트론


입력층 : 데이터를 입력받음
은닉층 :
출력층 : 원하는 값 데이터를 출력

딥러닝 또한 가중치를 찾아내는 과정
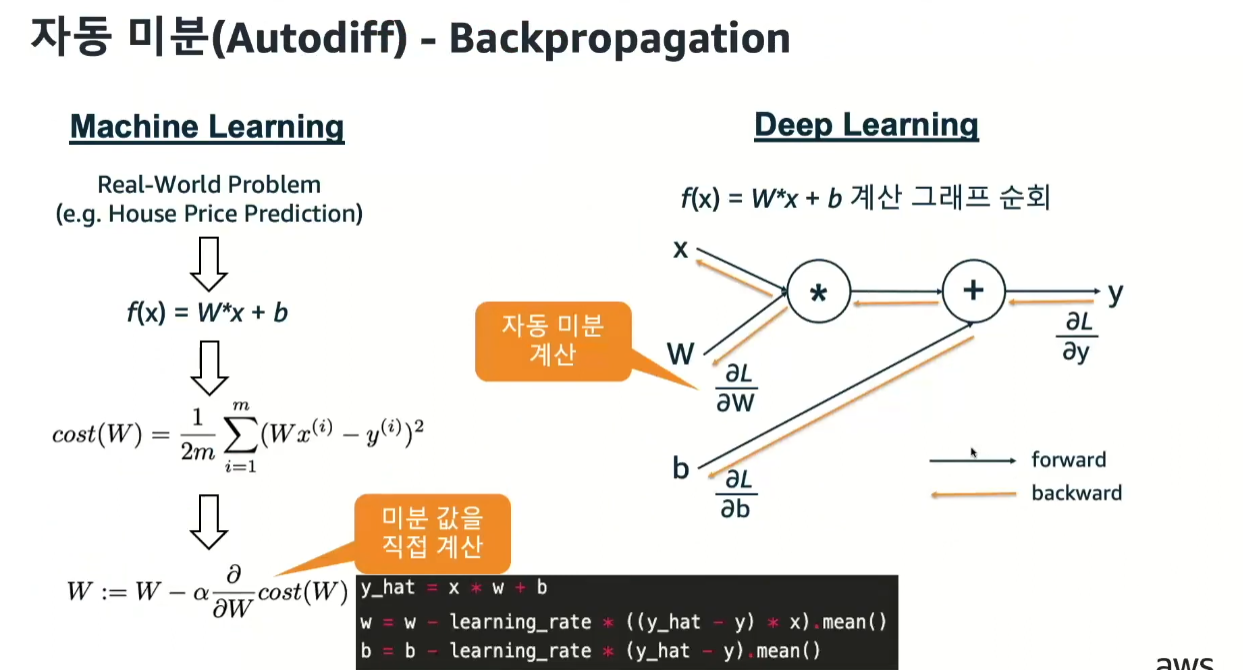
머신러닝 : 경사하강법을 사용하기 위해 미분을 사용하여 계산된 결과로 파라미터를 찾아감
딥러닝 : 직접 계산하기엔 파라미터가 너무 많아서 계산 그래프로 표현



코어수가 많고 병렬적으로 계산할 수 있는 GPU가 유리하다. ... 엔비디아..!!!

머신러닝의 경우 Feature extraction 의 작업이 필요하지만 딥러닝의 경우 은닉층에서 같이 수행됨


좋은 강의 감사합니다.