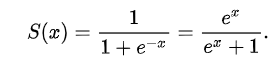(1의 모델에서 activation 을 sigmoid -> relu 로 바꾸고 learning_rate 만 1/10 로 낮추었음)
model2 = Sequential()# 뼈대를 세우는 클래스
#입력층
model2.add(InputLayer(input_shape = (28,28)));
model2.add(Flatten())# 2차원 사진데이터를 1차원으로 평평하게 만듬 28*28 = 784 개 pixel 데이터로 만듬
#중간층
model2.add(Dense(128, activation='relu'))
model2.add(Dense(256, activation='relu'))
model2.add(Dense(128, activation='relu'))
#출력층
model2.add(Dense(10, activation = 'softmax'))
#학습 및 평가방법 설정
model2.compile(loss='categorical_crossentropy',
optimizer = SGD(learning_rate=0.001,# momentum= .. 클래스로 SGD 를 불러오면 파라미터 조정이 가능
)
, metrics=['accuracy'])# 3개이상. 2진 - binary.. ,
model 3의경우 optimizer 를 SGD가 아닌 Adam 을 사용
model2를 수정 후 다시 시각화 하게되면 다음과 같이 나은 성능을 보인다.
기타.
- 기본 경사하강법 GD : 전체 데이터를 이용해 업데이트 -> 오래걸린다, ram 이 터진다. 기기적 한계 , 자원확보 어려움, - 확률적 경사하강법 : Stochastic Gradient Descent : SGD : 기본값으로 사용. keras - 32개 벤치 사이즈 . , - 모멘텀 : Momentum : 경사하강법에 관성을 적용해 업데이트 0.9 정도 넣음. - 네스테로프 모멘텀 : Nesterov Accelrated Gradient : 개선된 모멘텀 방식 - 아다그리드 : Adaptive Gradient : 학습률 감소 방법을 적용해 업데이트 : 시간이 지날수록 학습률을 낮춰서 천천히 이동